Convolutional Networks for Semantic Segmentation
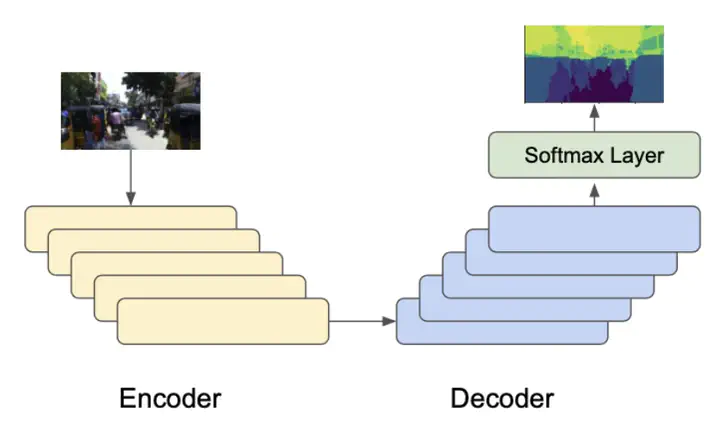 High-level architecture for baseline encoder-decorder CNN model.
High-level architecture for baseline encoder-decorder CNN model.In this paper, our goal is to apply an encoder-decoder network for the problem of semantic segmentation on the India Driving Dataset. Semantic segmentation belongs to the field of persistent problems in computer vision that requires high accuracy and efficiency, with applications in autonomous driving, robotics, and e-commerce. Our baseline model achieved a pixel accuracy of {\bf 0.699} and an Intersection over Union (IoU) of {\bf 0.159}. We worked to improve the results from a fully convolutional encoder-decoder network using various techniques including augmenting the dataset and addressing class imbalance, with the combination of techniques resulting in an accuracy of {\bf 0.691} and IoU of {\bf 0.144}. We further experimented to optimize the model by utilizing different architectures including changes to the activation function and number of layers, transfer learning, and U-Net implementation. Our best model, using transfer learning, sees a test accuracy of {\bf 0.723}, and a test IoU of {\bf 0.149}.
Margot Wagner
Postdoctoral Researcher
Interested in the use of data science and AI in mental health and using neuroscience to inspire next generation AI tools.