Image Captioning using an LSTM Network
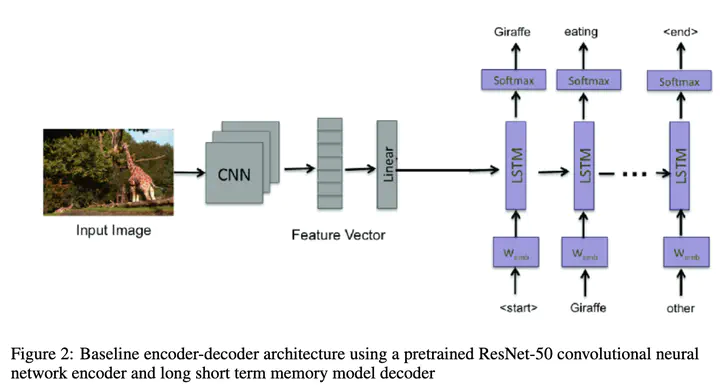
Image comprehension is becoming an increasingly important task in today’s world as the need to use large sets of images to answer questions about them becomes more pertinent. A first step in that direction, in this paper we try and label a set of images in the COCO dataset using a pre-trained ResNet 50 model (trained on ImageNet) to extract and encode the features of the images and an LSTM network as a decoder to generate the caption one word as a time. Our baseline model using an LSTM with a learning rate of 5e-4, embedding size of 300, and hidden size of 512 achieved a test loss of 1.796, BLEU-1 score of 53.471, and BLEU-4 score of 13.988. We experimented with variations to the model, including using a Vanilla RNN, using stochastic caption generation with different temperatures, and varying the learning rate, embedding size, and hidden size. Our best model used an LSTM with learning rate of 5e-5, embedding size of 800, hidden size of 2048 and deterministic generation, and achieved a test loss of 1.729, a BLEU-1 score of 61.172, and a BLEU-4 score of 18.711, demonstrating that LSTMs can produce successful results for Automatic Image Annotation (AIA).
Margot Wagner
Postdoctoral Researcher
Interested in the use of data science and AI in mental health and using neuroscience to inspire next generation AI tools.